You are here
Sharding do-it-yourself
Tue, 2022-02-15 12:18 — Shinguz
As already mentioned earlier, we roughly have a hand full of customers which are playing with the though of sharding solutions. They typically have many different customers (clients, tenants) and the number of customers becomes so huge (thousands to millions) that one machine cannot cope with the load any more.
So splitting the load by customers to different machines makes sense. This is quite easy when customers are separated per schema. In the good old times of Open Source our customers have implemented those solutions themselves. But nowadays it looks like do-it-yourself is not sexy any more. It seems like this core competence of a business advantage must be outsourced. So some vendors have already made some solutions available to solve this need: Sharding Solutions.
My question here is: Can a generic sharding solution build exactly what your business needs? Are you still capable to optimize your business process in the way you need it when you buy a 3rd party solution?
And: If you use another product, you have also to build up the know-how how to use it correctly. So I am really wondering if it is worth the effort? Buy or make is the question here. So we made a little Proof-of-Concept of a sharding solution. And it did not take too long...
The concept
First of all we have 2 different kinds of components:
- The Fabric Node - this is the database where all the meta information about the shards are stored.
- The Shards - these are the databases where all the customer data are stored.
And we need all this more or less in a highly available fashion.
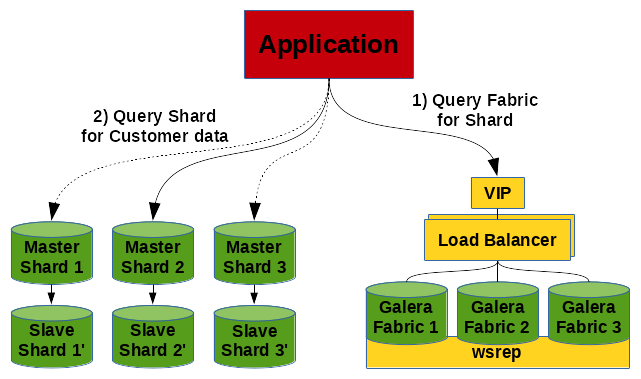
The fabric table can look as simple as this:
CREATE TABLE `tenant` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`tenant_id` varchar(128) NOT NULL,
`schema` varchar(128) NOT NULL,
`machine` varchar(128) NOT NULL,
`port` smallint(5) unsigned NOT NULL,
`locked` enum('no','yes') NOT NULL DEFAULT 'no',
PRIMARY KEY (`id`),
UNIQUE KEY `tenant_id` (`tenant_id`),
UNIQUE KEY `schema` (`schema`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
;
INSERT INTO tenant
VALUES (NULL, 'Customer 1', 'customer_1', '192.168.33.21', 3306, 'no')
, (null, 'Customer 2', 'customer_2', '192.168.33.22', 3306, 'yes')
, (null, 'Customer 3', 'customer_3', '192.168.33.23', 3306, 'no')
;
SQL> SELECT * FROM tenant;
+----+------------+------------+---------------+------+--------+
| id | tenant_id | schema | machine | port | locked |
+----+------------+------------+---------------+------+--------+
| 4 | Customer 1 | customer_1 | 192.168.33.21 | 3306 | no |
| 5 | Customer 2 | customer_2 | 192.168.33.22 | 3306 | yes |
| 6 | Customer 3 | customer_3 | 192.168.33.23 | 3306 | no |
+----+------------+------------+---------------+------+--------+
Connection
Now our application needs to know on which shard the data for a specific customer is stored. This will be found in the fabric. So our application has to do first a connect to the fabric and then a connect to the shard. To make it more transparent for your application you can encapsulate everything in one method. And if you want to optimize the connecting you can store the sharding information in a local cache.
$dbhFabric = getFabricConnection($aFabricConnection);
$aShardConnection = readShardConnection($dbhFabric, $aTenant);
$dbhShard = getShardConnection($aShardConnection);
// Do everything needed for the tenant...
$sql = sprintf("SELECT * FROM `customer_data` limit 3");
$result = $dbhShard->query($sql);
For the PoC we create 3 different schemas (customer_1, customer_2 and customer_3) with some customer data in it:
CREATE TABLE `customer_data` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`customer_name` varchar(128) NOT NULL,
`customer_data` varchar(128) NOT NULL,
`customer_number` INT UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
;
INSERT INTO `customer_data`
VALUES (NULL, 'Customer 3', 'Some data', ROUND(RAND()*1000000, 0))
, (NULL, 'Customer 3', 'Some data', ROUND(RAND()*1000000, 0))
, (NULL, 'Customer 3', 'Some data', ROUND(RAND()*1000000, 0))
;
Resharding
One of the challenges of such a construct is that the intensity of usage in the shards changes over time. All new customers are possibly placed in the same new shard. The new customers start playing around with your application. They do more and more. So a shard becomes overloaded sooner or later. Or the other way around: You have a lot of customers which were very enthusiastic about your product in the beginning and not so much any more now. So you loose customers on the older shards. Or you have to replace an old shard by newer hardware. All this leads to the situation, that your solution is not balanced any more and must be re-balanced. We call this resharding:
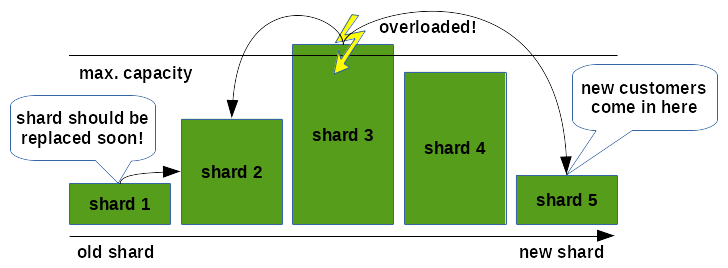
This can be done quite easily with a few commands:
-- Lock tenant UPDATE `tenant` SET `locked` = 'yes' WHERE `tenant_id` = 'Customer 3'; -- Wait some time until cache expires or invalidate cache mariadb-dump --user=root --host=192.168.33.23 --port=3306 customer_3 | mariadb --user=root --host=192.168.33.21 --port=3306 # Check error codes very well. Possibly do some other additional checks! -- Update tenant to new shard UPDATE `tenant` SET `machine` = '192.168.33.21', `port` = 3306 WHERE `tenant_id` = 'Customer 3'; -- DROP tenant in old shard mariadb --user=root --host=192.168.33.23 --port=3306 --execute="DROP SCHEMA `customer_3`" -- Unlock tenant UPDATE `tenant` SET `locked` = 'no' WHERE `tenant_id` = 'Customer 3';
Monitoring
To find out which customers cause a lot of load and which shards are over- or under-loaded you need some kind of sophisticated monitoring. You possibly want to know things like:
- CPU usage (
mpstat) - I/O usage (
iostat) - NW usage
- RAM usage (
free) - Number of connections per shard and per customer
- Number of queries per shard and per customer
- etc.
Those metrics can be found with some queries:
SHOW GLOBAL STATUS LIKE 'Bytes%';
SELECT *
FROM information_schema.global_status
WHERE variable_name IN ('Threads_connected', 'Threads_running', 'Max_used_connections')
;
SELECT processlist_db, COUNT(*)
FROM performance_schema.threads
WHERE type = 'FOREGROUND'
GROUP BY processlist_db
;
SELECT * FROM sys.schema_table_lock_waits WHERE object_schema LIKE 'customer%';
SELECT * FROM sys.schema_table_statistics WHERE table_schema LIKE 'customer%';
SELECT * FROM sys.schema_table_statistics_with_buffer WHERE table_schema LIKE 'customer%';;
SELECT table_schema, SUM(data_length) + SUM(index_length) AS schema_size
FROM information_schema.tables
WHERE table_schema LIKE 'customer%'
GROUP BY table_schema
;
Missing features
If you really think you need it, you can also make a nice GUI to show all those metrics. But be prepared: This will cost you most of your time!
We assume that all the shards are accessed with the same user as the fabric is accessed. In reality this is possibly not the case. But the tenant table can be easily extended.
To make the whole concept much easier we omitted the idea of number of replicas which is known from other solutions. We think having every shard redundant by a Master/Slave replication is sufficient.
If you find anything which is missing in this concept study or if you experience some problems we did not thought about, we would be happy hearing from you.
Challenges
Some challenges you have to solve if you implement sharding:
- Common tables/data: If you have some Master Data which are common in all Shards and which are updated from time to time you have to think about how to distribute the data on all Shards, and how to keep them in sync an consistent. Some ideas to solve this problem: Master/Slave Replication (one Shard is one Slave), write yourself a distribution job and check the tables periodically, use a Federated/Federated-X/Connect SE table to have only one source of data.
- You have to cut your Data in Shards in a way to avoid Cross Shard Joins. Think about the Cross Shard Joins twice!
Taxonomy upgrade extras:
- Shinguz's blog
- Log in or register to post comments